AI zmieniło sposób, w jaki piszę testy E2E — ale nie tak, jak można by się spodziewać. Nie chodzi o „AI pisze wszystkie testy za mnie”. Chodzi o eliminację tarcia w konkretnych, powtarzalnych zadaniach: generowaniu scenariuszy, analizie błędów, produkcji boilerplate’u. Kiedy AI robi te rzeczy, mam więcej czasu na to, co faktycznie wymaga myślenia — architekturę testów, dobór strategii selektorów, decyzje o pokryciu.
Ten artykuł to praktyczny przewodnik: gdzie AI realnie pomaga, gdzie nie, jak to wdrożyć w projekcie Playwright i czego się po tym spodziewać.
Gdzie AI faktycznie ma sens — i gdzie nie
Zanim wejdę w szczegóły, realistyczna mapa:
AI przyspiesza pracę. Nie zastępuje myślenia.
Architektura: AI jako warstwa w pętli jakości
Infografika poniżej pokazuje, jak AI wpasowuje się w standardowy pipeline E2E — nie jako zamiennik, ale jako dwie dodatkowe warstwy: przed implementacją (generowanie scenariuszy) i po wykonaniu (analiza błędów).
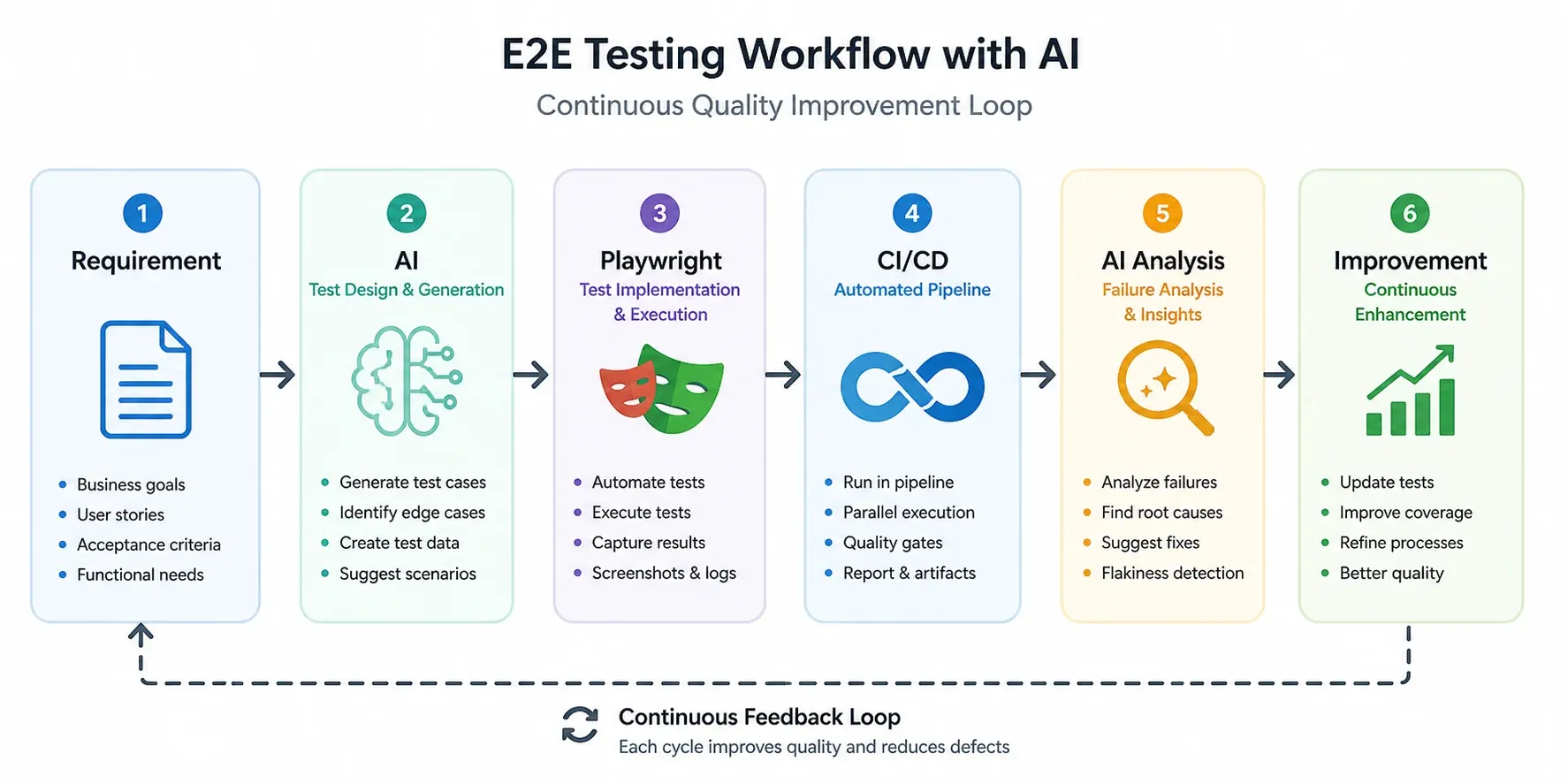
Kluczowe: AI pojawia się dwukrotnie. Raz na początku (projektowanie scenariuszy), raz na końcu (analiza wyników). Playwright i CI/CD pozostają bez zmian — AI je otacza, nie zastępuje.
Strategia selektorów — fundament stabilnych testów
80% problemów z testami E2E to selektory. Kruche, CSS-owe, zależne od struktury DOM, które sypią się przy każdym redesignie. Zanim zaczniesz generować testy z AI, ustal zasady selektorów — bo AI bez instrukcji domyślnie generuje złe.
Hierarchia selektorów
getByRole jest preferowany nie tylko ze względu na stabilność — testuje też dostępność aplikacji. Jeśli getByRole('button', { name: 'Zaloguj się' }) nie działa, przycisk prawdopodobnie nie jest dostępny dla czytników ekranu.
Specyfika Vue i Astro
W komponentach Vue z dynamicznym renderowaniem i w komponentach Astro z hydracją po stronie klienta, standardowe selektory CSS są wyjątkowo kruche. Kontrakt data-testid jest tutaj właściwym podejściem:
<!-- Vue -->
<button data-testid="login-submit" @click="handleLogin">
Zaloguj się
</button>
<!-- Astro (client:load) -->
<SearchForm client:load data-testid="search-form" />Zasada: testuj zachowanie, nie strukturę DOM. data-testid to kontrakt między testem a komponentem — zmiana stylów czy struktury wewnętrznej nie łamie testu.
Przykłady w praktyce
Admin Filament/Livewire: selektory semantyczne + czekanie na hydratację
Test z panelu admin Laravel, który utrzymuję (Filament v5 + Livewire). Sprawdza warunkowe UI: pole “kwota sprzedaży” ma się pojawiać tylko gdy status sklepowy to sprzedany.
// e2e/shop-status.spec.ts
test('should show sale value field only when status is sold', async ({ page }) => {
await page.goto('/admin/products');
await page.locator('a[href*="/admin/products/"][href*="/edit"]').first().click();
await page.waitForURL('**/admin/products/**/edit');
const forSaleToggle = page.getByRole('switch', { name: 'Na sprzedaż' });
const shopStatus = page.getByLabel('Status w sklepie');
// Przełącz "Na sprzedaż" off→on, żeby Livewire ponownie wyrenderował sekcję
if ((await forSaleToggle.getAttribute('aria-checked')) === 'true') {
await forSaleToggle.click();
await expect(shopStatus).not.toBeVisible(); // auto-wait, aż Livewire schowa sekcję
}
await forSaleToggle.click();
await expect(shopStatus).toBeVisible({ timeout: 15000 });
// 'available' → pole kwoty NIE jest widoczne
await shopStatus.selectOption('available');
const saleValue = page.getByRole('spinbutton', { name: 'Kwota sprzedaży (PLN)' });
await expect(saleValue).not.toBeVisible();
// 'sold' → pole kwoty JEST widoczne
await shopStatus.selectOption('sold');
await expect(saleValue).toBeVisible();
});Co ten test pokazuje w praktyce:
- Każdy cel assercji jest semantyczny —
getByRole('switch'),getByLabel,getByRole('spinbutton'). Jedyny CSS locator to link wejściowy (a[href*="/edit"]), na którym niczego nie weryfikujemy. - Jeden test, dwa stany — przełączenie dropdownu między
availableasoldpokrywa warunkowe UI w jednym round-tripie. Bez osobnego fixture per stan. - Web-first assertions obsługują timing hydratacji — zero
waitForTimeout.expect(shopStatus).not.toBeVisible()iexpect(shopStatus).toBeVisible({ timeout: 15000 })auto-retry’ują dopóki Livewire nie wyrenderuje. AI bez kontekstu domyślnie wstawiawaitForTimeout(1000)po każdej interakcji (“na wszelki wypadek”) — Playwright docs oznaczają to jako DISCOURAGED i tak rodzą się flaky suite’y. getAttribute('aria-checked')dla switchy —locator.isChecked()działa wyłącznie na<input type="checkbox|radio">i rzuca błąd narole="switch". Odczytaria-checkedbezpośrednio to obecnie poprawny wzorzec.
Hydratacja Astro: data-testid dla komponentów bez stabilnej roli
Gdy komponent jest hydrowany po stronie klienta (Astro client:load, Vue, React), a granica, do której chcesz się scope’ować, nie ma oczywistej roli semantycznej — data-testid jest kontraktem. Wzorzec:
<!-- SearchForm.astro -->
<SearchForm client:load data-testid="search-form" />// e2e/search.spec.ts
test('wyszukiwarka zwraca wyniki dla znanego zapytania', async ({ page }) => {
await page.goto('/');
const form = page.getByTestId('search-form');
await form.getByRole('searchbox').fill('astro');
await form.getByRole('button', { name: 'Szukaj' }).click();
const results = page.getByTestId('search-results');
await expect(results).toBeVisible();
await expect(results.getByRole('article').first()).toBeVisible();
});Dwie rzeczy warte uwagi:
data-testidscope’uje,getByRoleweryfikuje. Test ID identyfikuje granicę hydratacji; same interakcje (searchbox,button,article) nadal idą przez role semantyczne. AI bez tego niuansu doczepiadata-testiddo każdego elementu — to osobny anty-wzorzec.- Test ID siedzi na komponencie, nie na jego dzieciach. Jedno
data-testid="search-form"wystarcza — nie potrzebujeszsearch-input,search-submit,search-erroritd., chyba że element naprawdę nie ma żadnej roli semantycznej.
Prompty, które faktycznie działają
Jakość outputu AI jest wprost proporcjonalna do jakości promptu. Oto wzorce, które stosuję.
Generowanie scenariuszy testowych
Jesteś inżynierem QA. Wygeneruj scenariusze E2E dla funkcji: [opis funkcji].
Uwzględnij:
- ścieżka pozytywna (happy path)
- scenariusze negatywne (błędne dane, brak uprawnień)
- edge case'y (puste pola, bardzo długie wartości, znaki specjalne)
- przypadki bezpieczeństwa (jeśli dotyczy)
Format: lista punktowana. Każdy scenariusz: co robi użytkownik → co system powinien zwrócić.Generowanie kodu Playwright
Napisz test Playwright w TypeScript dla scenariusza: [scenariusz].
Zasady bezwzględne:
- używaj getByRole lub data-testid, nigdy CSS selectors
- każda akcja musi mieć assertion (expect)
- Page Object pattern — logika w klasie, nie w teście
- komentarze tylko tam, gdzie intencja nie jest oczywistaDebugging błędu
Analizujesz błąd Playwright. Podaj:
1. Prawdopodobna przyczyna (root cause)
2. Konkretna poprawka
3. Pewność odpowiedzi (0-100%)
Błąd: [stack trace]
Kod testu: [fragment kodu]MCP — od chatu do narzędzia inżynierskiego
MCP (Model Context Protocol) to specyfikacja pozwalająca modelom językowym na bezpośrednią interakcję z narzędziami. Przy Playwright praktyczny efekt jest konkretny: zamiast generować kod do skopiowania, AI steruje żywą sesją przeglądarki, czyta jej stan runtime’u i wnioskuje o luce między tym, czego test się spodziewał, a tym, co rzeczywiście zrobiła strona.
Bez MCP: AI = zaawansowany autocomplete. Kopiujesz kod, uruchamiasz, kopiujesz błąd z powrotem, wklejasz, iterujesz ręcznie.
Z MCP: AI otwiera przeglądarkę, reprodukuje kroki, pobiera output konsoli i odpowiedzi sieciowe, proponuje poprawkę w tej samej pętli.
Playwright MCP — co dokładnie jest w pudełku
microsoft/playwright-mcp daje Claude Code (lub innemu klientowi MCP) narzędzia do sterowania przeglądarką i inspekcji jej stanu. Te, których używam najczęściej:
browser_console_messages— pełny output konsoli (włącznie z błędami) od momentu załadowania strony, z filtrowaniem po levelu. Najbardziej użyteczne narzędzie, gdy strona po cichu sypie się na błędzie JS.browser_network_requests— wszystkie wywołania sieciowe strony.browser_network_requestzwraca pełne headers + body konkretnego — przydatne przy “form submit zwraca 422, co jest w odpowiedzi?”.browser_snapshot— drzewo accessibility jako tekst strukturalny. README MCP explicite zaleca to zamiast screenshotów dla LLM — dane strukturalne biją piksele w rozumowaniu.browser_take_screenshot— screenshot pikselowy, gdy faktycznie potrzebny kontekst wizualny (layout, kontrast, z-index).browser_route,browser_network_state_set— mockowanie requestów, toggle offline, przydatne do testowania stanów błędów.
Model dostarczania: pull, nie push. Serwer nie streamuje eventów do kontekstu modelu — Claude musi sam wywołać browser_console_messages (lub inny tool) po akcji, dla której chce telemetrię. Typowa pętla debuggingu: navigate → klik → poproś o konsolę + sieć + snapshot → wnioskuj o różnicy.
Gdzie to się realnie opłaca
Dwa scenariusze, w których MCP zmienia mój workflow:
- Walidacja błędów E2E. Test pada z
TimeoutError: waiting for locator. Bez MCP wklejam stack trace i zgaduję. Z MCP Claude nawiguje do tego samego URL, wołabrowser_console_messages(często runtime JS error blokujący hydratację), bierzebrowser_snapshot(żeby zobaczyć realne drzewo ról) i wskazuje rzeczywistą przyczynę — zwykle w sekundach od linii, która padła. Sam log konsoli to to, czego brakuje przy debuggingu opartym tylko na stack trace. - Weryfikacja zachowania komponentów na żywo. Szczególnie przydatne przy komponentach Vue / Astro
client:load, gdzie timing hydratacji albo brakujący prop daje cicho zepsuty UI. Claude może otworzyć stronę, wchodzić w interakcje z komponentem, czytać co mówi konsola i raportować, czy komponent wyrenderował, sypnął błąd, czy zhydratował się w połowie. Szybsze niż debugowanie przezconsole.log, a AI widzi ten sam runtime state, co ja.
Granica warta zapamiętania: playwright-mcp steruje żywą przeglądarką, nie odpala plików *.spec.ts. Do uruchamiania samego suite’a nadal używasz npx playwright test. MCP zarabia na siebie przy reprodukcji i diagnozie, nie przy odpalaniu test runnera.
Setup to jeden wpis w .mcp.json w głównym katalogu projektu (lub w claude_desktop_config.json dla Claude Desktop):
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": ["@playwright/mcp@latest"]
}
}
}Debugging z AI: 30 minut → 5 minut
Debugging to obszar, gdzie ROI jest najbardziej odczuwalny. Klasyczny pattern:
- Test failuje z błędem
TimeoutError: waiting for locator - Wklejam do Claude: stack trace + kod testu + opis co testuje
- AI identyfikuje: selektor jest poprawny, ale element pojawia się dopiero po animacji — brakuje
waitFor - Poprawka: jedna linia
Bez AI: 20–30 minut na przestudiowanie stack trace’a, sprawdzenie selektora w DevTools, wychodzenie dlaczego element nie jest dostępny. Z AI: 3–5 minut na skompletowanie kontekstu i ocenę sugestii.
Kluczowe zastrzeżenie: AI bez kontekstu generuje generyczne odpowiedzi. Stack trace + kod + opis środowiska — to minimum, żeby dostać użyteczną diagnozę.
Realne liczby: ile czasu oszczędza AI
Dane orientacyjne z moich projektów. Zakres zależy od złożoności aplikacji i jakości promptów. Kluczowe zastrzeżenie: AI nie przyspiesza architektury testów ani decyzji o pokryciu — tam czas pozostaje bez zmian.
Anty-wzorce, których unikam
Kopiowanie bez walidacji — AI generuje plausible-looking kod, który może mieć subtelne błędy logiczne. Zawsze czytam kod przed uruchomieniem.
Ślepe zaufanie do selektorów — domyślnie AI generuje CSS selectors, bo są proste. Trzeba to wymuszać promptem.
Brak architektury — generowanie testów bezpośrednio, bez Page Object pattern, daje szybki start i ból przy refactoringu.
Overengineering z MCP — dla małego projektu z kilkoma testami MCP to overhead. Zaczynam od prostego copypastu, MCP wprowadzam gdy projekt rośnie.
Podsumowanie
Testy E2E w 2026 roku to nie tylko kod Playwright — to system, w którym AI zajmuje się powtarzalnym, a inżynier skupia się na tym, co wymaga osądu.
Konkretne kroki na start:
- Zacznij od debugowania — wklej błąd do Claude z kontekstem. Natychmiastowy ROI, zero konfiguracji.
- Ustal zasady selektorów —
getByRole → data-testid → id, CSS tylko w ostateczności. Wbuduj to w prompt. - Generuj test cases, nie kod — AI jako brainstorm scenariuszy, Ty jako filtr jakości i implementacja.
- MCP gdy projekt rośnie — integracja z Playwright MCP ma sens przy regularnych cyklach debugowania.
Jeśli budujesz aplikację w Astro, Vue 3 lub innym nowoczesnym stacku i chcesz porozmawiać o strategii testowania — napisz.